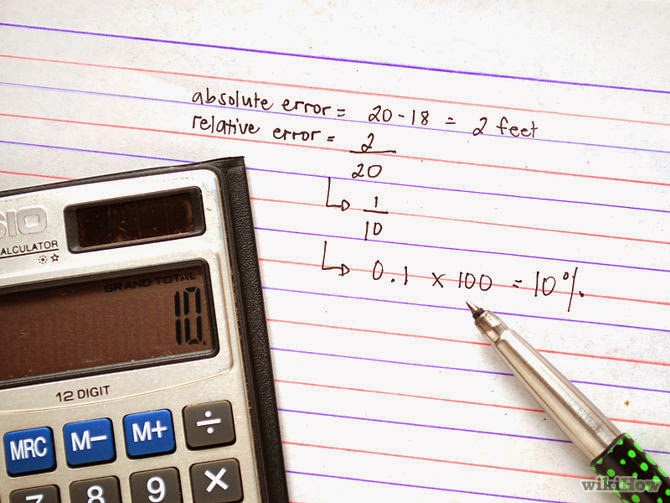Frecuencias
Una vez que se han recolectado los datos, debe organizarse y resumirse la información en una tabla de frecuencias, de forma adecuada y útil, para su posterior estudio. Una tabla de frecuencias es una ordenación simplificada de los datos estadísticos, en la que a cada valor se le asigna un número que representa la cantidad de veces que ha aparecido. Dicho número recibe el nombre de frecuencia, de la cual existen varios tipos:
 Frecuencia absoluta (fi).
Frecuencia absoluta (fi).
Es el número de veces que se repite una característica o valor dentro de un conjunto de datos, trátese de una población o de una muestra. A cada uno de estos valores se le conoce como clase.
Frecuencia relativa (hi).
Es el cociente entre cada frecuencia absoluta y el número total de datos (n, si es una muestra, o N, si es una población).
hi = fi/n hi = fi/N
La frecuencia relativa puede expresarse también en forma de porcentaje.
hi% = hi x 100%
Frecuencia absoluta acumulada (Fi).
Presenta un saldo acumulado de las frecuencias absolutas de los intervalos. Se calcula sumando la frecuencia absoluta acumulada anterior, más la frecuencia absoluta actual. En otras palabras, es la suma de las frecuencias absolutas de todos los valores inferiores o iguales al valor considerado.
Fi = Fi-1 + fi
Frecuencia relativa acumulada (Hi).
Presenta un saldo acumulado de las frecuencias relativas de cada intervalo de clase. Se calcula sumando la frecuencia relativa acumulada anterior, más la frecuencia relativa actual. En otras palabras, es la suma de las frecuencias relativas de todos los valores inferiores o iguales al valor considerado.
Hi = Hi-1 + hi
Así como con la frecuencia relativa, la frecuencia relativa acumulada puede expresarse como un porcentaje.
Hi% = Hi x 100%
Valor mínimo, Valor máximo y Rango.
Tratándose de variables cuantitativas, el valor mínimo y el valor máximo son la menor y la mayor cantidad que toma una variable en un conjunto de datos. El rango (R) es la diferencia existente entre esos valores máximo y mínimo.
R = Xmáx − Xmín
Ejemplo: Los siguientes datos corresponden a la talla, en centímetros, de una muestra de 30 recién nacidos durante el mes de enero de este año en cierto hospital:
54, 49, 49, 52, 49, 40, 50, 47, 50, 51, 49, 47, 51, 40, 47, 46, 48, 45, 51, 51, 47, 50,
48, 51, 51, 50, 48, 49, 47, 53.
Puede observarse que los valores mínimo y máximo son:
Xmín = 40
Xmáx = 54
De donde, el rango es: